








 发表于 2021-12-21 11:43
发表于 2021-12-21 11:43
3.多样性和分类法:何为分类法
任何类型的空间分析的基础是发展或选择一个令人满意的分类系统(Harvey 1969; Wilson, 2000)。与大多数经验性研究一样,空间分析研究提出了一系列丰富的个体,需要以某种方式进行分类,以便进行充分的研究,这就是上文威尔逊所说的部门实体。这种分类取决于调查的目的,同样的个体可以根据这些目的进行非常不同的分类。因此,开发一个适当的分类系统需要非常精确。同时,这也被证明是空间分析中最困难的任务之一。一般来说,分类被认为是 "基本程序,我们通过它将某种秩序和连贯性强加给来自现实世界的大量信息",并且[它]"被认为是构造现实以检验假设的一种手段"(Harvey, 1969)。这意味着分类系统的充分性不能独立于研究的目的进行评估。为了在理论和分类之间有一个适当的相互关系,一个主要问题或一个预设的假设的重要性经常被说明(Harvey, 1969)。正如Wilson所强调的那样,在延伸这一点时,我们应该意识到。"没有绝对正确的方法来做分类"(Wilson, 2000)。
在我们的特定案例中,对明确分类的需求来自于分析和测量城市空间的多样性的目的。选择类别的原则、类别的数量以及它们的属性,都会对最终的多样性数值产生关键的影响。例如,如果我们测量一个地区的主要功能的多样性,例如,分为居住和工作人口,这将与同一地区的经济部门的多样性非常不同,如官方、商业和工业部门。再往下看,测量商业部门的多样性,更具体地说,零售业,例如,可以根据提供的商品类型进行分类和排序,如衣服、鞋子和家具,这将产生不同的价值。这意味着,一个地区可能同时具有高多样性和低多样性,这都取决于所使用的分类。
在本文中,我们将使用基于OpenStreetMap和从OSM编码系统中提取的两种类型的多样性分类。使用OpenStreetMap的原因是可以比较一个国家内或几个国家的城市之间的差异。我们目前的研究重点是分析斯德哥尔摩一个城市,但作为更大的研究项目的一部分,有可能会扩展到其他城市。OSM分类是基于点数据的,包括零售和服务、食品、银行、酒店、健康、教育、公共设施、文化和体育等类别。它还提出了更细粒度的零售活动分类,包括食品和百货商店、服装、健康和美容、家庭、家具、电子产品、体育和文具以及书籍。基于这些数据,我们建议引入多样性的种类:城市层面的多样性(进一步称为一般多样性),以及地区或街道层面的零售多样性。选择零售业作为地方规模多样性的衡量标准是有道理的,因为它被普遍认为表明了城市中与行人有关的经济活动的强度(Scoppa & Peponis, 2015; Sevtsuk, 2014; Sevtsuk, 2010; Sevtsuk, 2010; Krafta, 1996)。这两个多样性指数都是用城市研究中常用的辛普森多样性指数来计算的(Talen,2008),可以很容易地转化为可及性测量。
4.方法论
一般的方法步骤包括测量多样性的因变量(1),测量差异化的自变量(2),通过控制街道中心度和建筑密度的变量来构建子模型(3),将因变量和自变量的数据连接到一个模型中(4),最后,对差异化的自变量和多样性的因变量之间的共变进行统计分析(5)。
景点,如居民或零售,但它也可以应用于建筑密度分析,将这种密度测量从基于面积的测量转化为基于位置的测量。PST是桌面软件Mapinfo的一个插件应用,它将空间语法与常规的可达性分析结合在一个工具中。
2 更高的半径没有被加入分析,如果更大的半径被应用于可及性分析,城市地区之间的差异甚至上升,这是由于测量的特殊性。
步骤1. 衡量一般和零售业的多样性
多样性的因变量是用辛普森多样性指数来衡量的,该指数被转化为可及性的测量。辛普森多样性指数是一个公认的衡量城市活动多样性的指标(Talen, 2008),而我们现在的问题是应该包括哪些类别。如前所述,我们建议使用基于OSM数据的两种多样性分类,涉及两个城市尺度:一般多样性和零售多样性。一般多样性(进一步称为Dgeneral),包括所有种类的基本城市服务(不包括办公室),这些服务更均匀地分布在城市中,而零售多样性(进一步称为Dretail)通常与重要城市中心与行人有关的经济活动的强度有关(Scoppa & Peponis, 2015; Sevtsuk, 2014; Sevtsuk, 2010; Sevtsuk, 2010; Krafta, 1996)。
两个多样性指数(Dgeneral和Dretail)被计算出来,并作为500米半径内的可及性来衡量。首先,计算每个独立类别的可及性,其次,计算类别总数的可及性,然后用所得数字计算辛普森多样性指数(D=Σ(n/N)2)。3 其中,n是每个类别中的活动数量,N是所有活动的总数量。
步骤2. 测量差异化的自变量
区分变量可以更简单地描述为地块大小,或者用可及性术语描述为地块的可及数量,因为如果地块较小,它们通常是很多(Bobkova, 2017a)。因此,根据上面的讨论,区分变量被测量为从每个地址点可获得的地块的绝对数量,跨越几个尺度或半径。500米、1000米和2500米的步行距离,并进一步被称为可访问的地块数量或可访问的地块(Aplot500、Aplot1000和Aplot2500)。
步骤3. 通过控制街道中心性和建筑密度构建子模型
为了评估差异化变量与两种不同的多样性的关系,必须控制另外两个空间形式的变量(街道中心性和建筑密度)。根据中心度的街道和根据密度的建筑物的类型已经在早期的研究中分析生成,在此用于我们选择测量变量的地点(Berghauser Pont等人,评论中),以便这些变量保持不变。
3 在辛普森多样性指数中,D的值越大,多样性就越低。为了使其更直观,D值从1中减去,所以最接近1的值意味着更高的多样性(1-D)
多尺度中心性街道类型是利用基于中心点的聚类法产生的,它通过不同的尺度,根据个人之间的中心性状况对街道段进行分类4 (Berghauser Pont, et al., in review)。聚类分析产生了五种中心度类型,其中只有两种类型("城市 "和 "邻里")的观测值被纳入我们的分析中,因为在其他三种类型中几乎没有发现经济活动。城市 "类型的街道在较高尺度上的中心度越来越高,"邻里 "类型的街道在大多数尺度上的中心度都很高,但在最局部的尺度上明显下降(同上)。
建筑密度类型是使用聚类分析(Berghauser Pont等人,2017),根据两个输入变量制定的。楼面空间指数(FSI)和地面空间指数(GSI)(Berghauser Pont & Haupt,2010),在500米步行距离内测量。聚类产生了六种密度类型,其中两种类型被选中用于我们的分析,因为与两种选定的街道类型类似,只有这些类型与大量的经济活动有关。两种选定的密度类型是 "密集型中层建筑”(城市中心的FSI和GSI的最高组合)和 "紧凑型中层建筑"(与 "密集型中层建筑 "相比,FSI和GSI值略低)。
4 对于街道类型,非机动车街道网络已经被使用,在500米到5公里的几个范围内测量了间隔中心性。
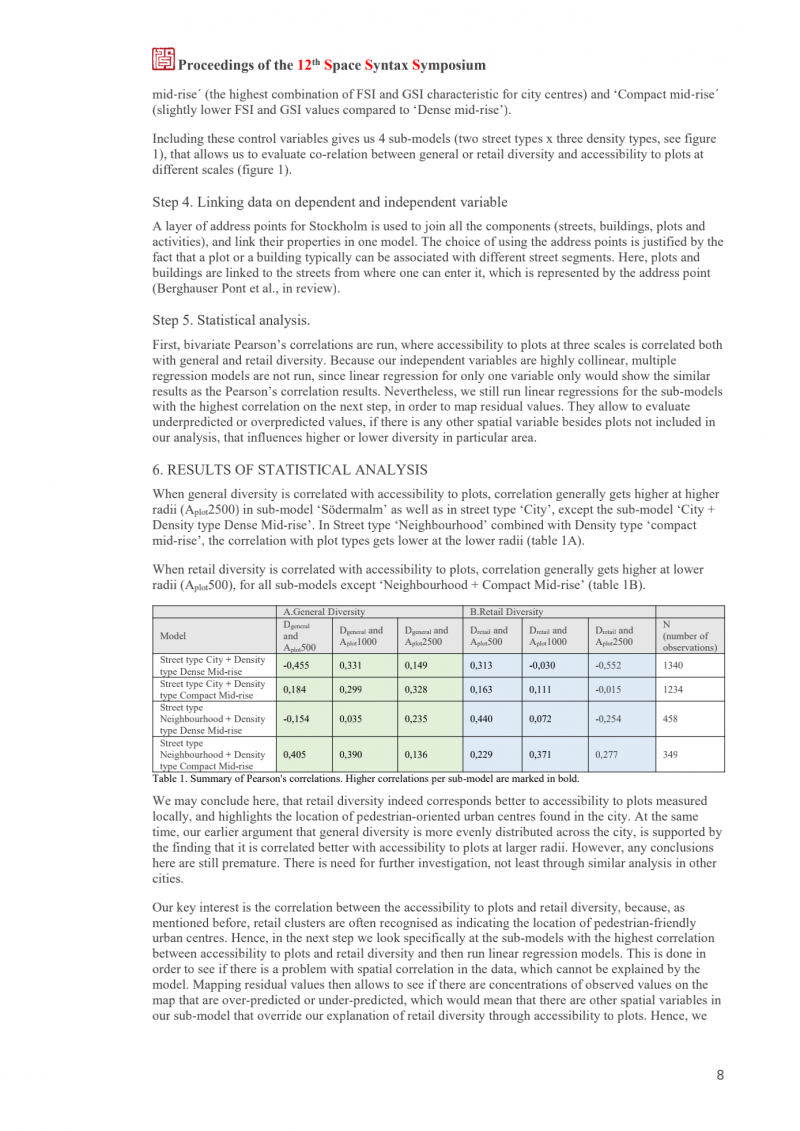
包括这些控制变量,我们得到了4个子模型(两个街道类型x三个密度类型,见图1),使我们能够评估一般或零售多样性与不同规模的地块的可及性之间的共同关系(图1)。
步骤4. 将因变量和自变量的数据联系起来
斯德哥尔摩的地址点层被用来连接所有的组成部分(街道、建筑、地块和活动),并在一个模型中连接其属性。选择使用地址点的理由是,一个地块或建筑物通常可以与不同的街道段相关联。在这里,地块和建筑被链接到人们可以进入的街道上,这些街道由地址点代表(Berghauser Pont等人,评论中)。
步骤5. 统计分析
首先,运行双变量皮尔逊相关,其中三个规模的地块的可及性与一般和零售多样性相关。因为我们的自变量高度相关,所以没有运行多元回归模型,因为只有一个变量的线性回归会显示与皮尔逊相关结果类似的结果。尽管如此,我们仍然对具有最高相关性的子模型进行了线性回归,以映射残差值。如果除了没有包括在我们的分析中的地块外,还有任何其他空间变量影响特定区域的较高或较低的多样性,它们允许评估预测不足或预测过高的值。


 收藏
收藏  支持
支持  反对
反对  回复
回复 呼我
呼我